Contact Tracing - How does it limit privacy?
The use of so-called Contact Tracing Apps for slowing the spread of Covid-19 is intensely discussed at the moment. We shed light on the workings of these Apps.
PEPP-PT, DP-3T? What does this all mean?
Recently there has been an intense public debate on so called contact tracing Apps in order to mitigate the spread of Covid-19. A contact tracing App allows a person diagnosed with Covid-19 to warn all people who have been in close proximity to the infected person within a recent time window during which infection was possible/likely. There are different ways of achieving such a functionality, and most recently there have been intense discussions about the most suitable approach.
A main concern in these discussions is the protection of users’ privacy (given that a lot of personal data such as location or people’s interaction patterns with their peers might get exposed). At the same time, it needs to be ensured that that a functional, and robust App is soon ready to be used – an App which does not consume too many resources (i.e. that does not require the transmission of huge amounts of data for the App users or time-consuming computations that might slow down mobile phones). Furthermore, it should be possible to use the App in different countries, so that contact tracing does not stop when crossing borders.
In order to achieve all these goals, the PEPP-PT consortium was created. PEPP-PT stands for Pan-European Privacy-Preserving Proximity Tracing. It is a European consortium that consists of European research institutions as well as (tech) companies interested in jointly pushing forward efforts for developing privacy-preserving contact tracing Apps. The goal of the PEPP-PT consortium has not been to come up with a single App to be used by all European countries, but rather to agree on a common interface for these Apps (so that they can interact with one another) and to develop different architectures for implementing this interface. These architectures were then meant to be further customized to the needs of the individual countries.
However, what is meant by architectures in this context? Two design principles for contact tracing Apps have emerged: a centralized one (where the users’ data is saved on a server that then evaluates whether certain users are at risk and notifies them) and a decentralized one (where only a minimal amount of data is uploaded to the server, so that users can download this information to compute locally whether they are at risk).
Initially, these two different approaches were pushed by different groups (=subprojects) within the PEPP-PT consortium. However, in the middle of April 2020, major disagreements caused the subproject pursuing the decentralized approach (called DP-3T, and led by the Swiss universities ETH Zurich and EPFL) to break away from the PEPP-PT consortium and to keep on working independently. The reason for this disaffiliation of DP-3T was that the researchers behind DP-3T felt that the PEPP-PT project was no longer striving for transparency. Instead, the PEPP-PT project pushed forward the centralized approach without providing a clear rationale for why this approach should be preferred over the decentralized one, which in turn promises better privacy guarantees.
In order to promote a better understanding of the advantages and disadvantages of the different approaches, we want to give an overview on how they work, how they use and expose data and how this can be problematic to the users’ privacy.
Clash of Cultures: Decentralized vs. Centralized
The general idea underlying the contact tracing Apps that are currently being discussed is to make use of a technology called Bluetooth Low Energy (short BLE). BLE is not the same as the classic Bluetooth which is, for example, used for connecting a mobile phone with wireless headphones. BLE is a similar technology that allows for transmitting a limited amount of information over very short distances (only a few meters). Nowadays, it is already widely used in many applications (such as fitness trackers). BLE has the advantage that it uses (as us captured in its name) less energy than classic Bluetooth. This ensures that its usage does not have a big impact on the phone’s battery life. BLE is supported by most modern smartphones, and (on most devices) it is enabled when enabling Bluetooth.
Via BLE, smartphones can send out small messages (also called beacons) that can be received by other parties for indicating that another device is close by. This technology is leveraged for proximity tracing: Every smartphone can send out identifiers and at the same time receive identifiers from other phones close by. The phone can save the identifiers it receives and thereby keep a log of other people’s phones to which it has come close to (e.g. over the last two weeks). These identifiers should not contain any personal information. They should be pseudonyms (e.g. random numbers) as otherwise personal data would be leaked immediately to other users. Furthermore, these identifiers should change frequently. Otherwise, a user could be easily tracked. For example, imagine a person that wants to know when or how often you pass by certain place (maybe because the person wants to know at what time you are usually not at home). The person would just need to determine your identifier once (by standing next to you) and afterwards it could just install a receiver somewhere that could log whenever you come by that place.
The two ideas outlined above ((1) having random looking identifiers as pseudonyms, and (2) having them change frequently) are common to both approaches, the centralized, and the decentralized one. However, the approaches differ in the way how a Covid-19 infection would be reported and how a user at risk would be notified. We prepared little overview charts for the two approaches and will describe them. Note that the description is slightly simplified and does not include all details - but it conveys the overall idea of how the centralized and the decentralized approach work.
Centralized
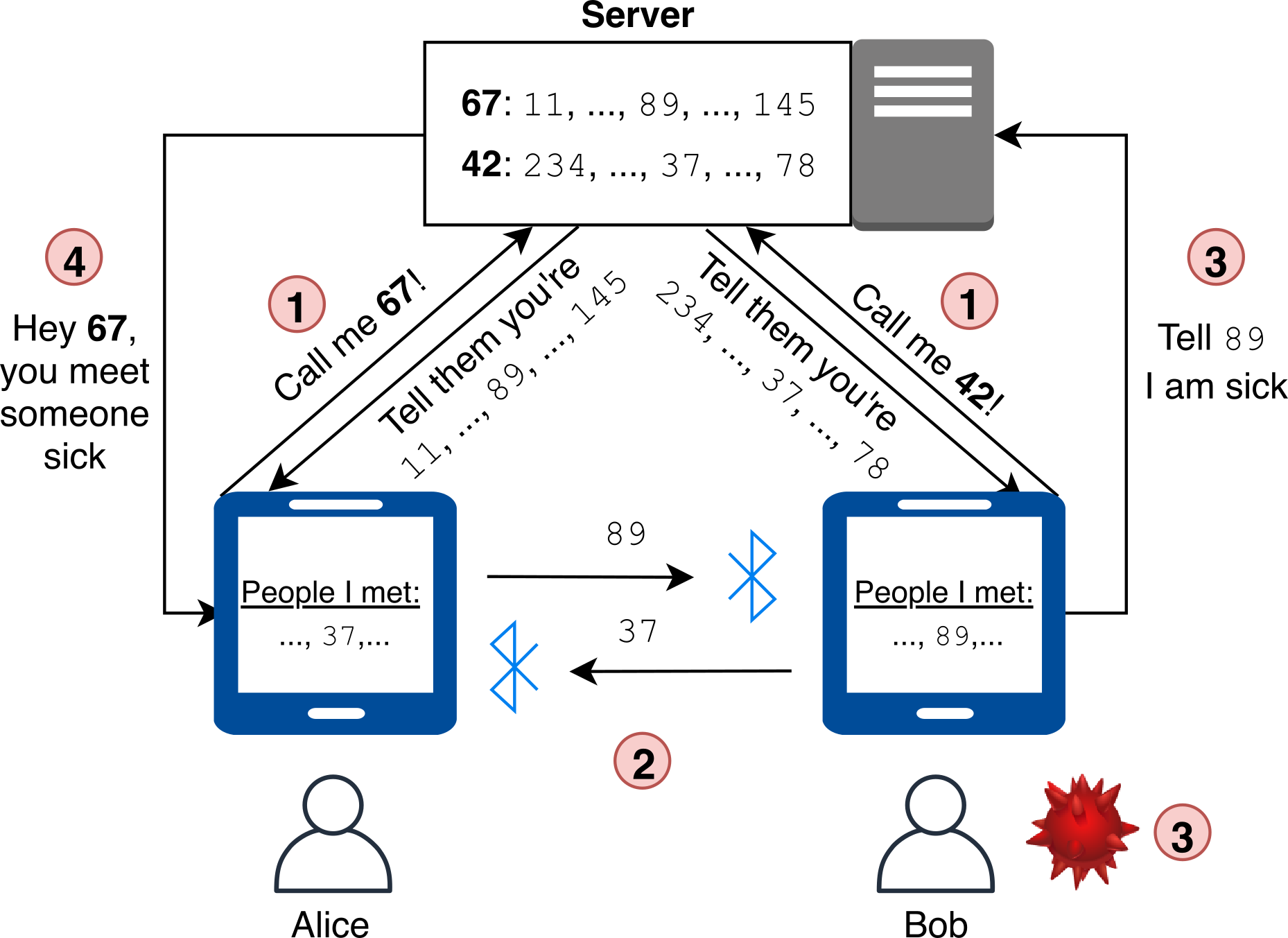
The key feature underlying the centralized design is a server (run by the government, or some health institution) that knows a persistent identifier for each user. The identifier can also be used to contact the user (e.g. by triggering a notification in the users App). The server generates temporal identifiers for each user and sends them to the user’s phone. These temporal identifiers are then used as the changing pseudonyms that are sent out to other users’ phones. This ensures that the server can keep track for each temporal identifier and the permanent identifier (user) it belongs to. If a user tests positive for Covid-19, they can notify the server. The notification could be authorized by a doctor or health agency by providing the infected user with some sort of authorization code that can be verified by the server. When notifying the server, the user should send along all the temporal identifiers of other people that the user collected during the infection window. Based on this list of temporal identifiers, the server can look up to which permanent identifiers they belong and send out a notification to these users to inform them that they are at risk. Some more advanced computation assessing the risk of a specific person would also be possible – for example, only people that have had several contacts with the infected person could be notified.
Decentralized
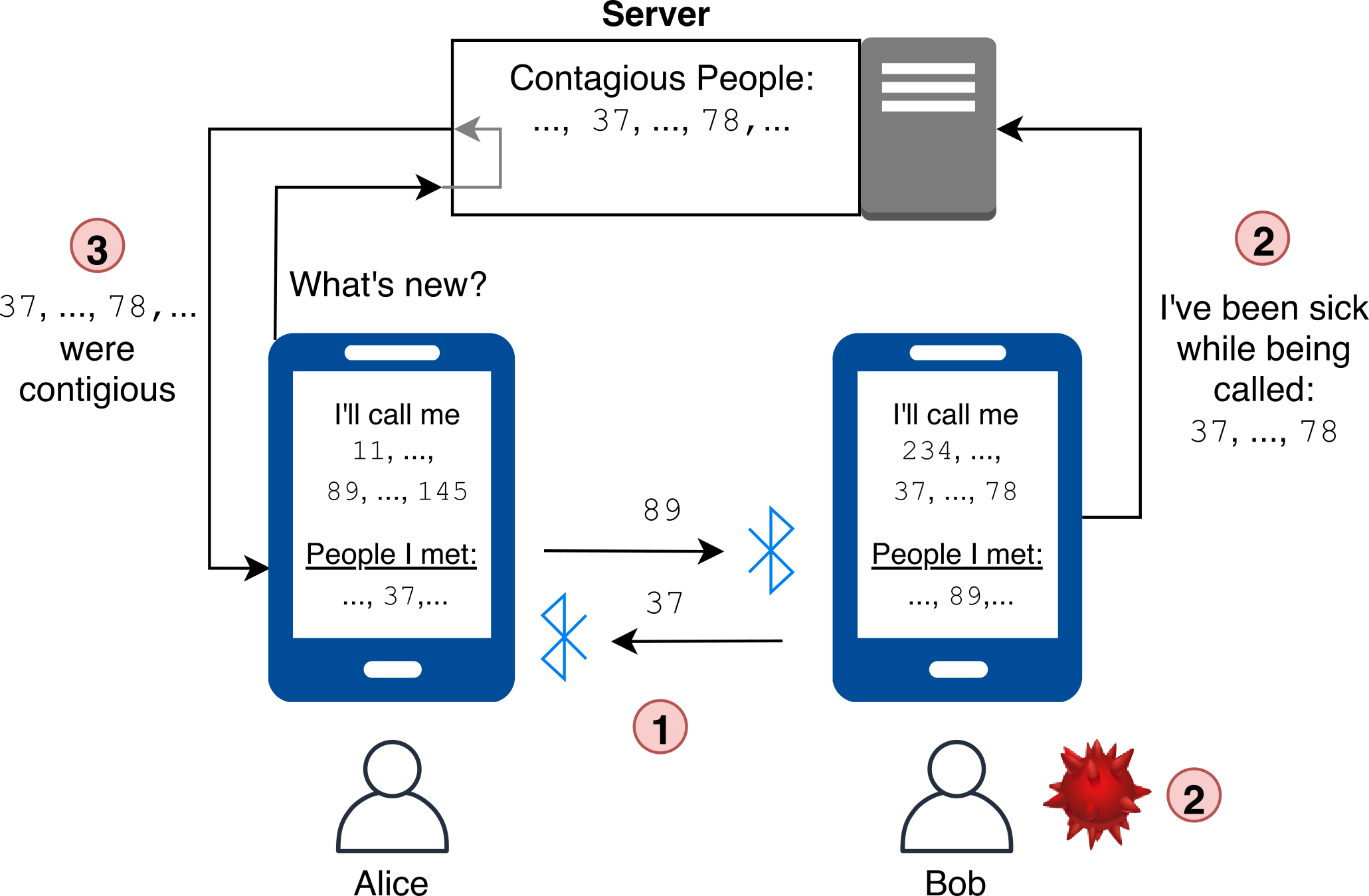
With the decentralized approach, the server does not create the temporal identifiers for the users. Instead, the users’ phones create these identifiers themselves, and consequently users do not register with a central server in the first place. However, a server (again run e.g. by the state or health organization) is used to enable the users to announce that they are infected: If a user tests positive for Covid-19, they can notify the other people by uploading all their own temporal identifiers that they have been sending out (e.g. over the last two weeks). The phones of the other users frequently download these identifiers (or rather a compressed representation of them that allows for fast lookup). They then check locally, in the list of temporal identifiers that they have come into contact with recently, whether they encountered any of the downloaded temporal identifiers of infected users. As a result, the server does not learn about who had a contact with an infected person - every user only learns this privately.
Privacy
Privacy, in general, is not a binary concept. An App is not either privacy-preserving or not-privacy preserving, it might be even hard to say whether one App is more privacy-preserving than another. In the end, it always depends on which information is exhibited to whom, and on how problematic the knowledge of a certain form of data by a certain entity is thought to be. Furthermore, one always needs to consider that it might be impossible to achieve a certain functionality without revealing certain pieces of information. For this reason, when evaluating the privacy of an App (or actually anything) one needs to do that with respect to the functionality that shall be achieved. Thus, it is important to have a very clear idea about the desired functionality of an App. In our case, the functionality (as claimed by PEPP-PT) should be that a person that has been in contact with an infected person is able to retrieve this information. The goal is not for the government or scientists to access this information (even though such a voluntary option for such data sharing could also be supported in the App). Consequently, the goal of a privacy preserving tracing App should be to exhibit a minimal amount of data while still being able to achieve this functionality.
There is some information that cannot be avoided to be shared when wanting to achieve this functionality. In the case of a contact tracing App that uses BLE and allows for dynamic registration (so everyone can create an account without particular verification), a person could find a way to learn which of their contacts got infected. As a person can dynamically create new accounts for each encounter with a person, they can identify which contact is infected with the help of the account on which they are notified about the infection of a contact.
Other forms of information leakage, however, heavily depend on the concrete architecture and implementation. The big goal of contact tracing Apps (in terms of privacy) is to leak as little information about the users’ identity or habits as possible - the goal is to make users stay anonymous: To achieve this, existing design architectures (the centralized and the decentralized one) make heavy use of pseudonyms (random identifiers are used instead of personal data). However, pseudonymity alone does not ensure the anonymity of a person. Another important factor is that a person’s different pseudonyms should not be linkable to one other. Otherwise, a person can be easily tracked. We will provide a short overview on how and by whom pseudonyms can still be linked in the different approaches, and how they consequently have an increased risk of being de-anonymized and tracked.
- The centralized design gives the server the capability to fully link the pseudonyms of all users, no matter whether they got infected with Covid-19 or not. This is because the server can link each temporal identifier to the corresponding persistent identifier. This enables tracking of users by everyone having access to the server.
- However, normal users of the system cannot link different encounters of the same user, regardless of whether they are infected or not. The only thing they learn are the changing pseudonyms of people they encounter. In case that they met an infected person, the server only sends them this piece of information.
- If in the centralized setting a user reports to be infected, they transfer information on all their contacts to the server. This allows the server to learn who might be at risk. However, it also implies that the server learns about the the user’s entire interaction pattern within the time period under question - the server learns with which persistent pseudonyms the infected user has been in contact and also how often.
- In the decentralized design, in contrast, the server never obtains information about a user that is not infected (even if this person has been in contact with an infected person). This is because a non-infected person never sends information to the server - instead the person only downloads information. Furthermore an infected person never tells the server anything about the people they met.
- However, normal users of the system learn (to some extent) which pseudonyms (temporal identifiers) of an infected user might belong together when downloading them from the server. This is as all newly downloaded temporal identifiers belong to the (potentially small) group of infected users that uploaded their identifiers in the period after the last download. Consequently, these identifiers are (depending on the size of the group) more likely to belong to the same user. This information can help a user of the system to retrospectively correlate encounters with different temporal identifiers (of an infected user) to correspond to the same person.
- If, in the decentralized setting, a user reports their own identifiers to the server, the server does not learn who is at risk and hence also knows nothing about the infected users’ interaction patterns.
We hope that the above list provides a rough overview of how the privacy of the centralized and the decentralized systems compare. Of course, there are way more details to be considered when doing a thorough privacy analysis. For example, we did not consider here that some coarse-grained timing information might be send along when notifying a person about an infection, which might allow for more correlations. The DP-3T project provides several documents where they analyze different systems. Furthermore, a detailed privacy assessment (available in English and German) conducted by the German non-profit organization FIfp compares both approaches.
To give a personal summary and assessment of the privacy of the two approaches: The privacy of the decentralized approach seems way better. It does not leak information about non-infected people to some central authority and such an authority also does not learn about the interactions between users - in this regard, it is strictly better concerning privacy than the centralized approach. A drawback of the decentralized (as compared to the centralized) approach is that other users might be able to link the pseudonyms of an infected user (since they learn about the user’s temporal identifiers, an information they would not receive in the centralized system). However, this linkage is limited to a specific time period, and depends (as mentioned above) on how many new infections are reported by the server at once.
One should note that privacy is not the only concern when it comes to contact tracing Apps. Security is also important: for example, it is crucial that an attacker cannot easily prevent the system from working by flooding it with false alarms. We will talk about such issues in another blog post.
Wouldn’t learning more information be better?
One question that arises when it comes to mitigating the ongoing Covid-19 pandemic is of course whether learning more data could be useful, e.g. for analyzing how the virus spreads. The easy answer would be Yes: the more data is exposed, the more can be learned from it – for the good and for the bad. For this reason, as discussed above, it is crucial to clearly define the aim/functionality of an App upfront and to decide which functionality is crucial, and which one is desirable. One can then potentially release Apps that allow for different privacy levels at the benefit of advanced functionality (and among which users can voluntarily select). The earlier presented approaches actually allow for a limited form of voluntary data donation: In case, that a user had contact with an infected person, they can voluntarily decide to send data about encounters with infected users in some past time window. This data would then not be sent to the state-controlled server but to selected epidemiologists. Also, there are other applications that are explicitly made for data donations (such as the data donation App by the German RKI). We will cover the working and privacy considerations for such Apps in another blog post.
What do Google and Apple have to do with this?
Google and Apple announced to partner up to assist the development of (privacy preserving) contact tracing Apps. Their plan to help is structured into two phases: First (until the middle of May), they plan to provide APIs for iOS and Android. An API (= Application Programming Interface), is a way to allow developers to access certain functionalities of the operating system that cannot be programmed natively in the applications. The APIs that Apple and Google plan to provide will contain functionalities for accessing the subset of keys/identifiers of an infected user that is to be shared with their recent contacts. They will also contain functionalities for calculating the resulting risk of infection for a user given such a set of identifiers from infected users. As can be seen from this description, Google and Apple follow a decentralized approach: They assume that the risk assessment will be done locally on a user’s device. Indeed, they are following an early draft of the DP-3T project, even though the DP-3T project encourages them to also take the latest enhancements to their approach into account. In a second phase, Apple and Google want to provide their own Apps that will be integrated into the operating system. This would imply that users would not need to install an App in the first place, and that such an App could be faster. However, such an App would probably not be open source, an issue that we will discuss later.
Another interesting question is to which extent the support of Apple and Google is needed for developing usable contact tracing Apps in the first place: One of the first European contact tracing Apps (the Stopp Corona App by the Austrian Red Cross), ran into a major challenge. With this App, the communication between the phones did not happen by only sending out identifiers via BLE. In the case of an encounter, a more involved protocol (called handshake) between the two meeting phones was executed. However, the big mobile operating systems (iOS by Apple and Android by Google) did not allow for such a protocol being triggered automatically (without explicit consent by the users). Therefore, users needed to manually confirm each encounter, which obviously made using the App cumbersome. For this reason, it was initially discussed whether Apple and Google should provide software support for enabling an automated handshake. With the solution proposed by DP-3T however, no such additional modifications are needed. Still, there is the problem that ideally a contact tracing App should actually run in the background of the mobile phone (so it should not be required that the App is open and focused all the time). However, having BLE running in the background is not straightforward on iOS and Android. In particular in the case of iOS, Apple would need to grant a specific approval for Apps doing so. For this reason, the APIs planned by Google and Apple would make the implementation of contact tracing Apps a lot easier. Still, developing Apps for the DP-3T and PEPP-PT proposals would also not be completely impossible without these APIs.
Why are people asking these Apps to be open source?
Even if the design of an App is done as described and approved by the user, this of course does not ensure that exactly this design (with all security and privacy considerations) is implemented in this way. An App could easily send more information to the server (e.g. location data of the senders, information on the device that they are using, or personal/contact identifiers that go beyond the required period). This would move beyond the idea of minimizing data sharing and would be totally out of control of the user. It is also always possible that simple programming flaws unintentionally cause security and privacy problems. By having the App released open source the program code of the App is publicly available. This allows researchers and other technically interested people to check the code for compliance with the promised functionality. The App by the Austrian Red Cross has been made publicly available on April 24th and can now be accessed here. Also, all prototypes of the DP-3T project can be found here.
Which Apps will be created now? And when?
Initially, many European countries followed the centralized approach pushed forward by PEPP-PT. By now, however, several countries have switched and are pursuing a decentralized approach following the DP-3T design. In particular, Austria, Switzerland, and Germany made corresponding announcements. This can also be traced back to the fierce discussion in the scientific community, and an open letter signed by over 300 scientists that criticized the increased privacy risks by the centralized as opposed to the decentralized approach.
In Austria, the development towards DP-3T is advanced within the scope of the Stopp Corona App by the Austrian Red Cross. This App was any early version of a decentralized contact tracing App, developed before DP-3T. It makes use of an adhoc-decentralized infrastructure that did not yet benefit from the joint design efforts of the DP-3T project, and hence shows some privacy weaknesses. The SBA research institute, together with the association epicenter.works and the non-profit organization NOYB recently completed a security analysis of the Stopp Corona App pointing out these weaknesses. As a consequence, the Austrian Red Cross incorporated several security enhancements and declared that they plan to switch to the DP-3T design long-term. To achieve this goal, they are in contact with scientists from the DP-3T project, as well as with Google and Apple. A concrete timeline as of when this change in design will happen has not yet been fixed.